
Research Data Management
These web pages provide guidance on managing, preserving and sharing research data, with information about University support
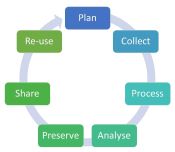
About research data management
Learn what Research Data Management is and what it involves at the University of Reading. Read the policies of the University and funders on research data, and find out about University support and other resources.
Data management planning
Find out why and how to write and prepare a data management plan in support of your grant application/research project. We provide guidance on funders' data management plan requirements, working with personal and confidential data, intellectual property rights in data, and using secondary data.
Managing your data
We provide practical guidance on managing data on a day-to-day basis during your research. Find help on data storage and backup, file naming and organisation, file formats, quality control, and documentation.
Preserving and sharing data
Learn how to use data repositories to preserve data and make them accessible to others at the end of a research project, how to prepare data for archiving, how to license datasets, and how to reference data from research publications.
Essential information for researchers (PDF)
Essential information for research students (PDF)
Contact us
Robert Darby, Research Data Manager
Tel. 0118 378 6161